
Skolan och dess bortglömda genetiska komponent (Del 5)
Skolan och dess bortglömda genetiska komponent (Del 5)
Tvillingstudier i alla ära men var finns generna för högre utbildningsnivå? I denna del sammanfattar jag de stora molekylärgenetiska studierna på området.


Sedan 1970-talet har tvillingstudier som har undersökt en mängd utbildningsutfall visat att en betydande andel av de individuella skillnaderna i både skolprestationer och utbildningsval förklaras av ärftliga faktorer. Samtidigt mäter tvillingstudier varken några gener eller miljöfaktorer, utan baseras på antaganden om såväl genetisk som miljömässig samstämmighet mellan tvillingar.
Så sent som för ett decennium sedan ifrågasatte många kritiker huruvida det överhuvudtaget fanns några “utbildningsgener”. Så vad har de molekylärgenetiska studierna egentligen funnit? Det ska vi lära oss mer om i den här delen.
Disposition
Identifiering av “utbildningsgener”
Grundläggande genetik
Vanligt förekommande genvarianter
Hur genomförs helgenomstudier?
Den första studien
Var finns genvarianterna?
Den andra studien
Genetiska korrelationer
Den tredje studien
Genetiska könsskillnader?
Heterogena samband
Hur beräknas polygena index?
Hur informativa är polygena index baserade på den aktuella studien?
Vad har de identifierade genvarianterna för biologiska funktioner?
Mer omfattande genetiska korrelationer
Den fjärde studien
Bättre polygena index för utbildning med större helgenomstudier
Är polygena index användbara på individnivå?
Innebär detta att det polygena indexet är värdelöst?
Direkta vs. indirekta genetiska effekter
Är polygena index informativa för alla etniska grupper?
Sammanfattning
Identifiering av “utbildningsgener”
Forskare som hade intresse för att studerade den genetiska bakgrunden till utbildningslängd insåg tidigt att enskilda forskargrupper inte kunde nå betydande framsteg genom att analysera sina egna databaser med DNA-prover från deltagare. Denna begränsning beror på beteendegenetikens “fjärde lag” som stipulerar att komplexa fenotyper (utfall) såsom utbildningslängd är polygena, nämligen att de förklaras av ett större antal genvarianter som var för sig har svaga effekter men vars sammanlagda effekt är betydande. För att möjliggöra identifiering av relevanta genvarianter krävdes det således gigantiska datamaterial som låg utanför ramen för vad enskilda forskargrupper kunde samla in på egen hand. Av det skälet etablerade ett antal forskarlag ett konsortium för att studera utbildningslängd och andra samhällsvetenskapligt relevanta utfall under namnet Social Science Genetic Association Consortium (SSGAC).
För att identifiera de relevanta genvarianterna genomförs så kallade helgenomstudier (eng. genome-wide association study, eller GWAS). Metodens namn kan dock vara något missvisande då den, av tekniska och ekonomiska begränsningar, inte kan analysera all genetisk variation, utan fokuserar på vanligt förekommande genvarianter. Vad menas med det?
Grundläggande genetik
Föreställ dig en svindlande siffra: 30 till 37 biljoner! Det är ungefär hur många celler den mänskliga kroppen hyser (Hatton et al., 2023). Var och en av dessa celler är en mikroskopisk värld i sig, och inuti dem finns en molekyl som bär på vår genetiska kod: DNA (deoxyribonukleinsyra).
Tänk dig DNA som en lång, vridande stege. Stegens sidor, som utgör "ryggraden" på DNA-molekylen, är gjorda av alternerande sockerarter (deoxiribos) och fosfatgrupper. Tvärs över stegen sitter “pinnarna” som utgörs av fyra olika kvävebaser: adenin (A), tymin (T), guanin (G) och cytosin (C) som spelar avgörande roller i allt från lagring av genetisk information till replikation och reparation av DNA-molekylen.
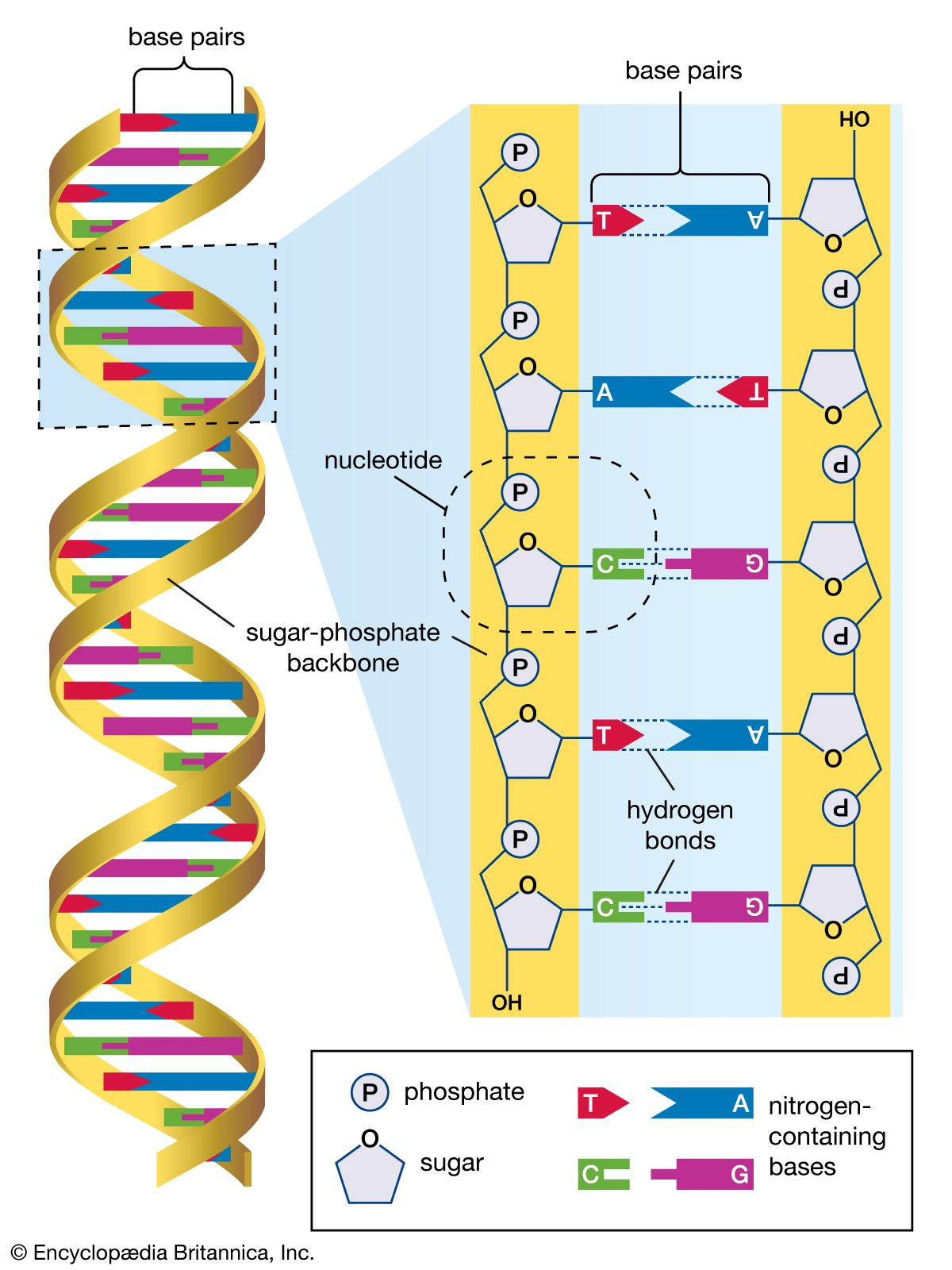
Varje kombination av “ryggrad” och “pinne” kallas för en nukleotid. Av figuren ovan framgår det att A alltid parar ihop sig med T medan G på liknande vis alltid parar ihop sig med C. Vi kallar dessa par av kvävebaser baspar. Det är ordningen av basparen som utgör varje individs unika genetiska kod, som styr hur våra proteiner byggs upp och vilka funktioner de ska ha. Proteiner är i sin tur avgörande, från att bygga upp våra vävnader och organ till att styra våra tankar och känslor.
Varje cell i vår kropp rymmer en imponerande mängd genetisk information; ungefär tre miljarder baspar och som är förpackade i en enskild DNA-molekyl. Det går att likna detta vid en bok med tre miljarder sidor, där varje sida innehåller information om våra individuella drag, från ögonfärg och kroppslängd till benägenhet för sjukdomar och beteenden. Vårt DNA bär således på enorma mängder data. Att effektivt lagra och organisera denna information i den mikroskopiska cellmiljön kräver därför en sofistikerad struktur.
Här träder histoner in i bilden. Histoner är proteiner som fungerar som spolaxlar runt vilka DNA-molekylen lindas. Varje enhet av åtta histoner bildar en nukleosom, som kan sägas vara en kompakt struktur där DNA-strängen slingrar sig runt histonerna. De kompakta nukleosomerna organiseras sedermera i längre strukturer som kallas kromatinfibrer. Dessa fibrer packas ytterligare genom att de viks och slingrar sig runt proteinkärnor, vilket resulterar i bildandet av de välkända X-formade strukturerna som vi känner igen som kromosomer.
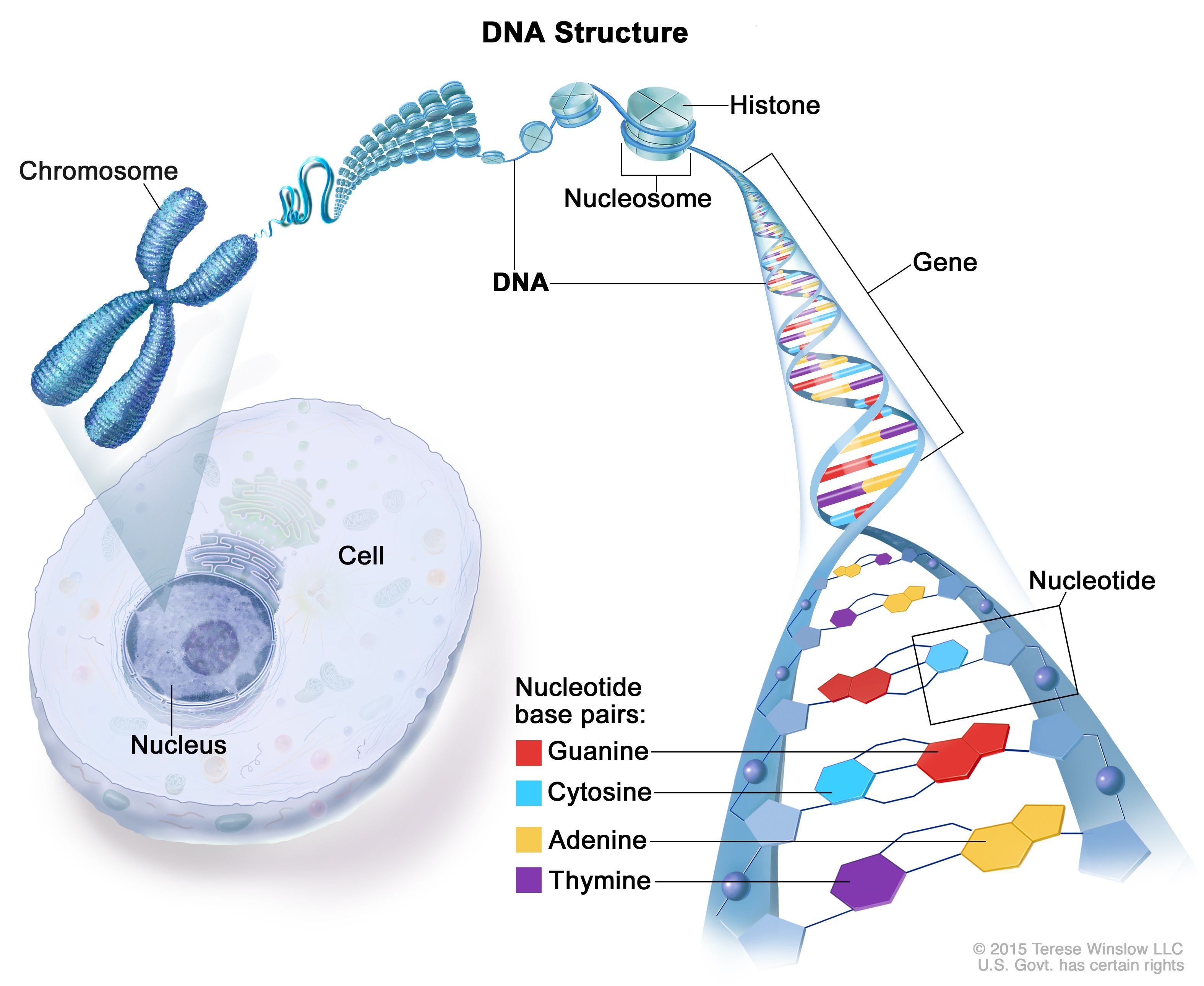
Var kommer generna in i bilden? När vi pratar om gener menar vi specifika segment av DNA-molekylen som har olika funktioner. Liknelsen vid en bok med tre miljarder sidor, där generna utgör enskilda kapitel med eget innehåll och funktion, används ofta i populärvetenskapliga sammanhang. Men verkligheten är mer komplex. Endast vissa regioner av gener, så kallade exoner, kodar för proteiner. Andra regioner, introner, har andra funktioner. Under en längre tid har de senare felaktigt kallats "skräp-DNA", men nyare forskning visar att de spelar en avgörande roll i flera viktiga processer.
DNA lagras som bekant inne i cellkärnan. För att proteiner, cellens "arbetshästar", ska produceras, måste informationen i DNA-molekylen transporteras till ribosomerna, vilka finns utanför cellkärnan. Ribosomerna kan ses som mikroskopiska maskiner som ansvarar för proteinsyntesen — processen att skapa proteiner från aminosyror. Aminosyror utgör de grundläggande byggstenarna för proteiner som ribosomerna kopplar samman i en specifik ordning enligt instruktioner från DNA:t.

Inuti cellkärnan finns enzymet RNA-polymeras, vars uppgift är att kopiera informationen från DNA:t och skapa RNA (ribonukleinsyra) genom en process som kallas transkription. Den vanligaste typen av RNA kallas budbärar-RNA (eng messenger-RNA eller mRNA) och har till uppgift att transportera den genetiska informationen från DNA:t till ribosomerna. För att budbärar-RNA ska kunna bildas krävs att intronerna, alltså de icke-kodande regionerna i DNA:t, "klipps bort" från molekylen i en process kallad splicing. Genom att intronerna avlägsnas under RNA-splicing blir budbärar-RNA-molekylerna tillräckligt små för att kunna transporteras ut ur cellkärnan. Notera att exoner enbart utgör mellan cirka 1 till 1,5 procent av människans DNA.
När budbärar-RNA-molekylen är färdigbildad vandrar den ut från cellkärnan och når ribosomerna. Ribosomerna fångar i sin tur upp den och "läser" av den genetiska informationen, sekvens för sekvens. Varje sekvens kodar för en specifik aminosyra och tillsammans bildar de en kedja av aminosyror som kallas för en polypeptid. Denna polypeptidkedja viks sedermera för att i slutändan bli ett färdigt och funktionellt protein.
Att kalla introner “skräp-DNA” är missvisande av två skäl. Dels reglerar de genuttryck genom att påverka hur ofta gener aktiveras och producerar protein, dels bidrar de till att olika versioner av proteiner skapas. Det senare sker i samband med att intronerna på olika vis avlägsnas från budbärar-RNA-molekylen.
Vanligt förekommande genvarianter
Det nedanstående diagrammet presenterar DNA-sekvenser från tre fiktiva individer. De sex första och sista nukleotiderna (ATGAGG samt CATACG) är identiska hos samtliga tre individer. Den sjunde nukleotiden skiljer sig emellertid åt: individ 1 har cytosin (C), individ 2 har tymin (T) och individ 3 har adenin (A) i den positionen.

Inom genetiken kallas variationer i enskilda nukleotider, eller baser, för enbaspolymorfier (eng. single nucleotide polymorphisms eller SNPs). Termen "polymorfi" härstammar från grekiska och betyder "många former". För att betraktas vara en vanligt förekommande genvariant måste enbaspolymorfierna återfinnas hos minst en procent av populationen.
Hur genomförs helgenomstudier?
Ponera att vi vill genomföra en helgenomstudie för att se vilka enbaspolymorfier (SNPs) som är associerade med utbildningsnivå med ett antal deltagare i Sverige. Vi samlar inledningsvis in DNA-prover från deltagarna, vilket antingen kan ske genom saliv- eller blodprover, och ber dem rapportera sin högsta uppnådda utbildningsnivå.
I nästa steg behöver vi identifiera vilka enbaspolymorfier deltagarna bär på. DNA-sekvenser extraheras därför från proverna och bryts ner till mindre fragment som sedermera märks med fluorescerande molekyler (molekyler som fångar ljus och avger det i andra färger). De märkta DNA-fragmenten appliceras på en SNP-mikromatris (eng. SNP microarray), en slags apparat med miljontals mikroskopiska prober fästa på dess yta. Varje prob är specifik för en viss enbaspolymorfi. Om ett DNA-fragment matchar en prob, avges en fluorescerande signal. Denna signal registreras av en skanner och omvandlas till digital data. Genom att analysera den fluorescerande signalen kan scannern således identifiera vilka enbaspolymorfier deltagarna bär på.1 Detta möjliggör i sin tur oss att genomföra helgenomstudien där sambanden mellan varje enskild enbaspolymorfi och deltagarnas högsta uppnådda utbildningsnivå undersöks.
När vi är färdiga med analysen kommer vi att ha en lång tabell med samtliga genvarianter och deras effektstorlekar. Tabeller av den här typen kallas för sammanfattande statistik (eng. summary statistics) och används för att genomföra kompletterande analyser, exempelvis ärftlighetsanalyser baserade på enbaspolymorfier, genetiska korrelationer mellan olika utfall och funktionella analyser av genvarianternas biologiska funktioner.
Den första studien
Det dröjde fram till cirka ett decennium sedan innan SSGAC-forskarna publicerade den första helgenomstudien som fokuserade på att förstå individuella skillnader i utbildningsnivå. Resultaten presenterades i artikeln "GWAS of 126,559 individuals identifies genetic variants associated with educational attainment" som publicerades i Science (2013). Forskarna hade analyserat två urval av deltagare; ett primärt datamaterial som omfattade cirka 101 000 deltagare och ett replikationsurval om cirka 25 000 deltagare, som användes för att de skulle säkerställa sig om att analyserna inte berodde på slumpen.
Forskarnas mätningar av uppnådd utbildningsnivå bestod av två kompletterande tillvägagångssätt. För det första utvärderade de antalet utbildningsår (EduYears), en variabel som harmoniserades för att möjliggöra jämförelser mellan studier från länder med olika utbildningssystem. För det andra registrerade forskarna huruvida deltagarna hade en avklarad högskoleexamen (College).
Studien identifierade en vanligt förekommande genvariant som var associerad med antalet utbildningsår och två sådana som var associerade med avklarad högskoleexamen. Därutöver upptäcktes ytterligare sju regioner i genomet som visade ett något svagare, men potentiellt betydande, samband med uppnådd utbildningsnivå.
I replikationsurvalet kunde forskarna finna stöd för de tre vanligt förekommande genvarianterna som var associerade med utbildningsutfallen. De sju regionerna som hade ett svagare stöd i primäranalysen visade sig inte bli replikerade. Forskarna kunde således enbart vara relativt säkra på de tre identifierade genvarianterna.
Med tanke på den etablerade kunskapen om de svaga individuella effekterna av vanligt förekommande genvarianter, och med beaktande av att studien endast identifierade tre sådana varianter, framstår det inte som oväntat att den sammanlagda effekten av dessa varianter endast förklarade två procent av den individuella variationen i utbildningsnivå.
Var finns genvarianterna då?
Vanligt förekommande genvarianter blir tilldelade unika ID-nummer som kallas för “rs ID” efter "Reference SNP cluster ID". De tre genvarianterna som identifierades i den aktuella studien hade följande ID-nummer: rs9320913, rs11584700 och rs4851266. Med hjälp av databasen dbSNP kan vi inhämta mer specifik information om genvarianterna. Låt oss ta den första genvarianten som exempel:
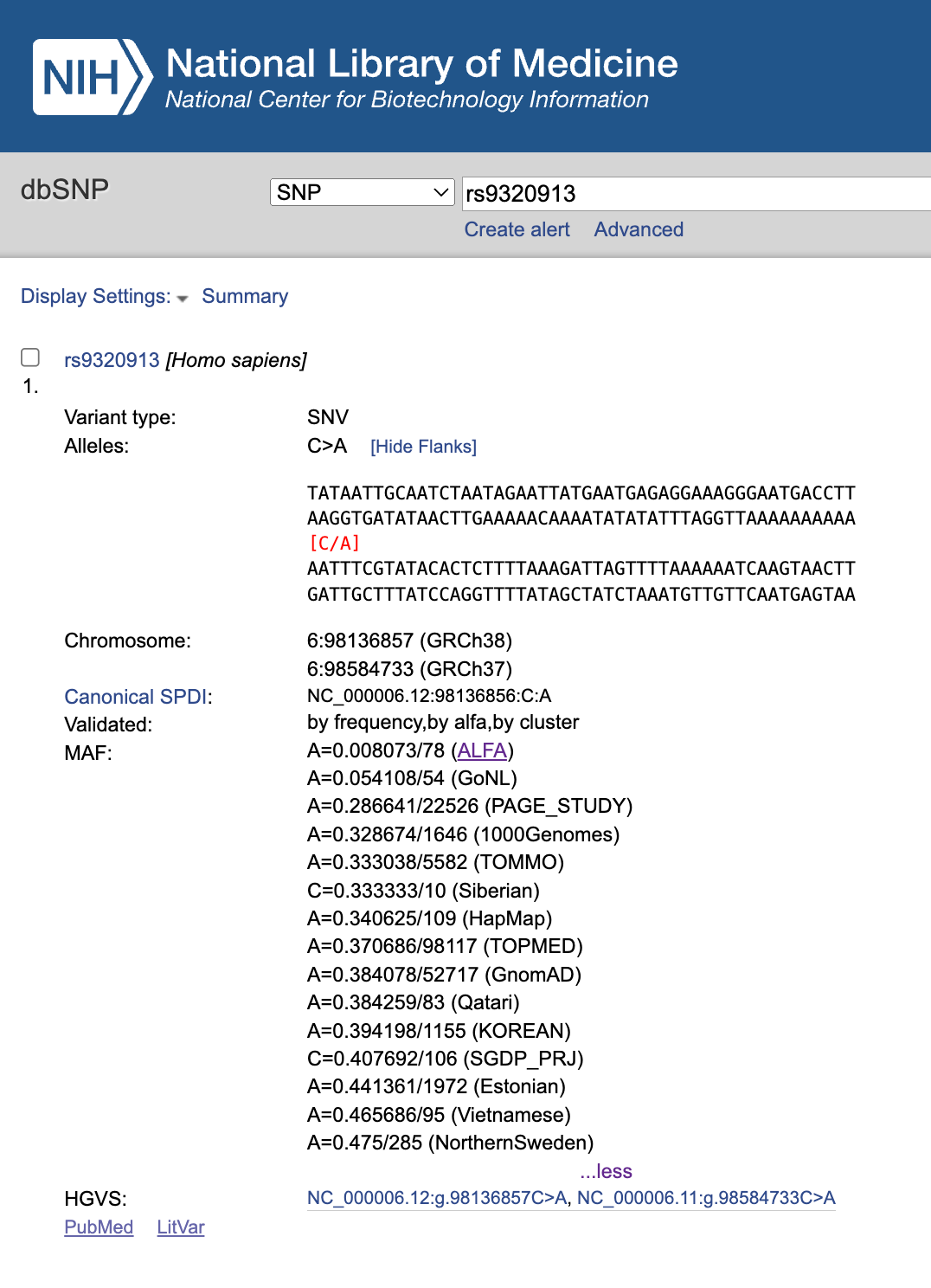
Här kan vi se att genvarianten återfinns bland människor (homo sapiens sapiens) där majoriteten har cytosin (C) i nukleotiden men att somliga istället har adenin (A). Vi kan därefter se den exakta positionen av nukleotiden i den sjätte kromosomen (exempelvis position 98136857 i referensdatabasen GRCh38). I fältet MAF (minor allele frequency) kan vi se hur pass vanliga de olika kvävebaserna (C och A) är i olika genomiska datamaterial. I datamaterialet från norra Sverige hade 47,5 procent av de 285 analyserade kromosomerna adenin istället för cytosin i den specifika nukleotiden. Fördelningen av genvarianter varierar som bekant mellan befolkningar vilket, tillsammans med mätfel, reflekteras i listan. På liknande vis kan vi även inhämta grundläggande information om övriga genvarianter.
Efter publiceringen av artikeln befann jag mig mitt i min forskarutbildning och erinrar mig tydligt av debatten kring resultaten. Från ett kritiskt samhällsvetenskapligt perspektiv innebar fynden i praktiken en obefintlig effekt av genetiken. Det fnystes åt det faktum att forskarna trots ett material som omfattade över 100 000 individer inte ens kunde förklara en enda procent av variationen i utbildningsnivå. Detta kunde enligt deras förmenande knappast betraktas utgöra ett betydande resultat.
Från ett beteendegenetiskt perspektiv representerade studien emellertid ett betydande framsteg. Forskarna hade visat att metoden fungerade och att det, med hänsyn till beteendegenetikens fjärde lag, endast var en tidsfråga innan mer omfattande datamaterial kunde samlas in och fler genvarianter identifieras.
Den andra studien
Tre år senare återvände forskarkonsortiet med artikeln "Genome-wide association study identifies 74 loci associated with educational attainment" i Nature. Under dessa år hade forskarna lyckats tredubbla urvalsstorleken till strax under 294 000 deltagare. De hade därtill ett replikationsurval som omfattade över 111 000 deltagare. Detta möjliggjorde för forskarna att identifiera 74 regioner i det mänskliga genomet, så kallade loci, som var associerade med individuella skillnader i utbildningslängd.
Resultat från helgenomstudier presenteras ofta visuellt i form av en Manhattan-figur (se nedan). Denna figur visar associationer mellan vanligt förekommande genvarianter och utbildningslängd. Varje punkt i figuren representerar en vanligt förekommande genvariant och är sorterad efter den genomiska region den tillhör. X-axeln visar i sin tur i vilken kromosom respektive locus återfinns. Punkternas färger skiftar mellan mörk- och ljusblå mellan kromosomer för att underlätta identifiering. Punkter som placerar sig ovanför streckade horisontella linjen på y-axeln betraktas vara statistiskt signifikanta. Något förenklat kan man säga att sådana samband osannolikt utgörs av slumpfynd.
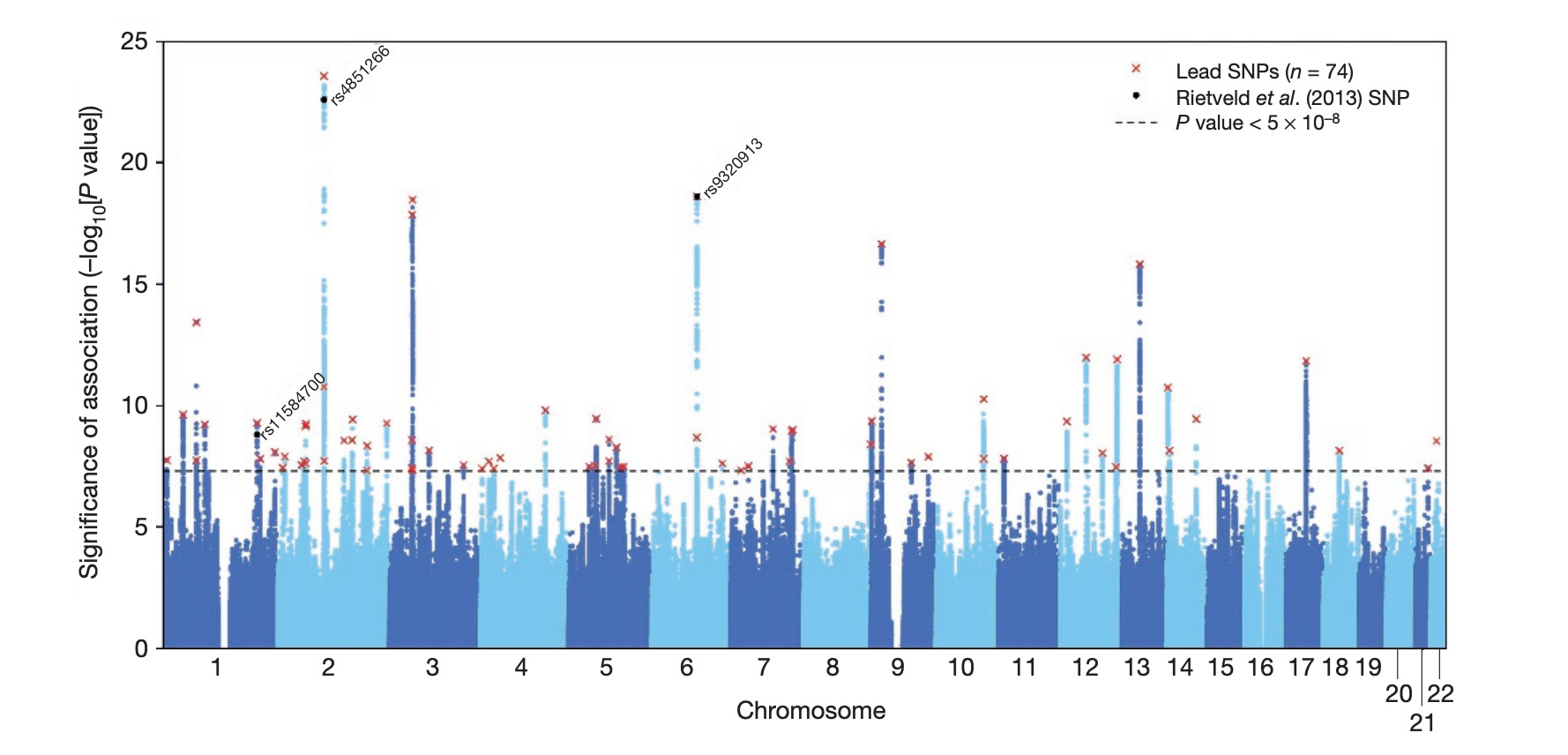
Inom varje region kallas den genvariant (enbaspolymorfi, SNP) som har starkaste evidensen för statistisk signifikans för en ledande SNP (eng. lead single nucleotide polymorphism [SNP]) och dessa är markerade i den ovannämnda figuren med röda kryss. Vi kan även se att de tre genvarianter som identifierades i den första studien replikerades i den aktuella studien (svarta cirklar). Två av dem utgör dock inte längre en ledande SNPs i sina respektive regioner med det uppdaterade datamaterialet. Forskarna fann totalt 74 ledande SNP:ar i lika många loci.
Manhattan-figuren illustrerar emellertid inte effektstorlekarna för de observerade associationerna, vilka, i enlighet med förväntningarna, var ytterst marginella. De 74 identifierade regionerna kunde var för sig förklara mellan 2,7 och 9 veckors variation i utbildningslängd.
Genetiska korrelationer
När genetiska studier når en tillräcklig statistisk styrka för att identifiera fler genvarianter, öppnar det upp nya möjligheter att undersöka hur genvarianter för olika utfall samverkar med varandra. Detta görs genom att man analyserar genetiska korrelationer, som belyser den grad till vilken genvarianter som är associerade med ett visst utfall överlappar med genvarianter för ett annat utfall.
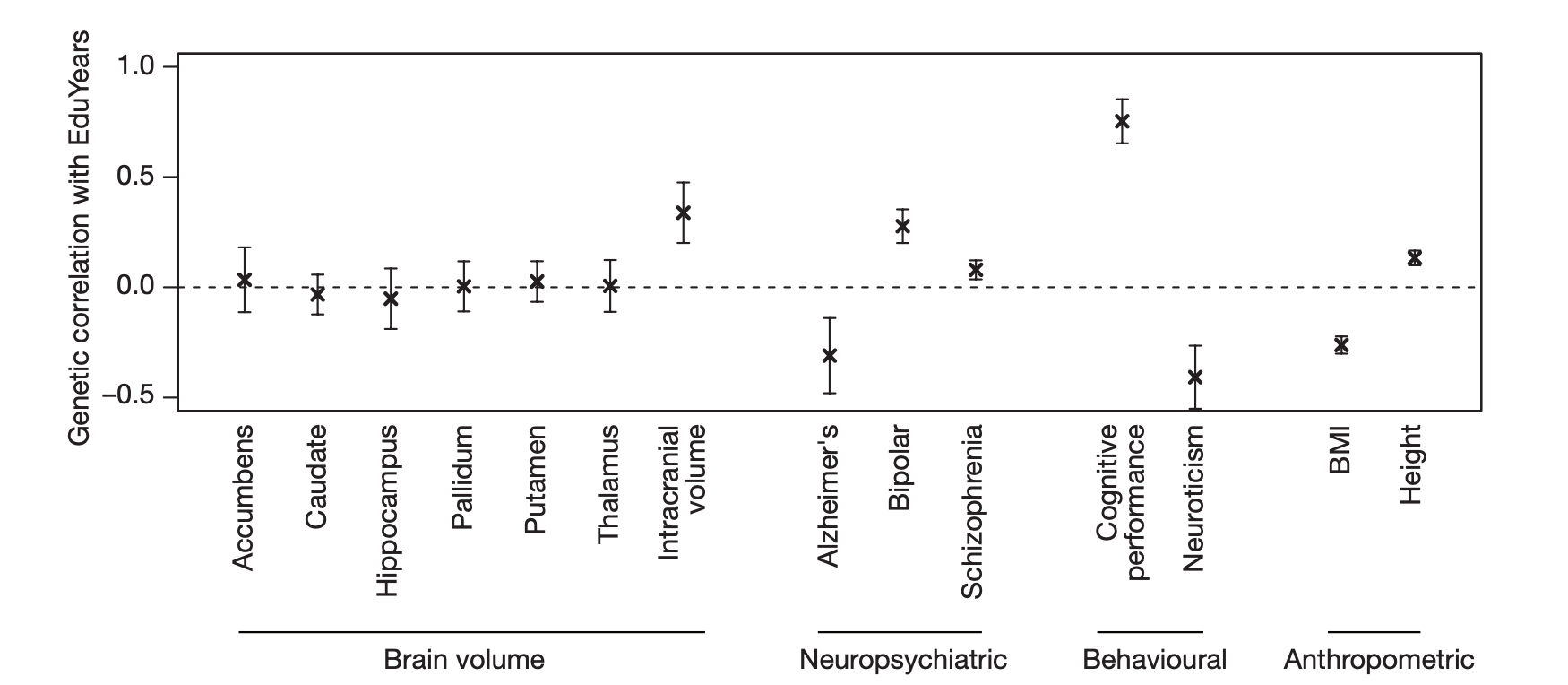
I den aktuella studien fann forskarna att genvarianter associerade med högre utbildningsnivå korrelerade med genvarianter som var associerade med större intrakraniell volym, eller enklare uttryckt större volym av skallens innehåll. De fann emellertid inga starkare genetiska korrelationer med volymmått på specifika regioner i hjärnan. Däremot visade det sig att genvarianter som var associerade med högre utbildningsnivå även var associerade med genvarianter med lägre risk för Alzheimers sjukdom men med en samtidig högre risk för psykossjukdomar, såsom schizofreni och bipolär sjukdom. I väntad ordning identifierade forskare en stark positiv korrelation med såväl intelligens (eng. cognitive performance) som kroppslängd. Samma genvarianter var dock negativt korrelerade med såväl neuroticism2 och kroppsmassa (eng. body mass index eller BMI).
Den tredje studien
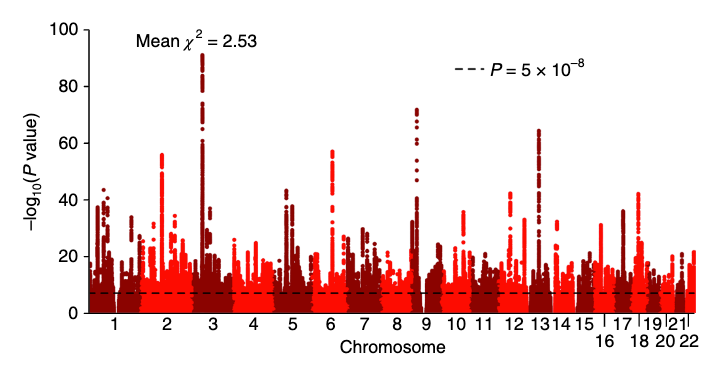
Efter ytterligare två år återvände konsortiet med artikeln "Gene discovery and polygenic prediction from a 1.1-million-person GWAS of educational attainment" i Nature Genetics. Denna gång hade man utökat urvalsstorleken från strax under 300 000 deltagare till 1,1 miljoner deltagare. Detta resulterade i identifieringen av 1 271 vanligt förekommande genvarianter som var associerade med utbildningslängd.
Av Manhattan-figuren nedan kan vi dels se det stora antalet genvarianter som ligger ovanför gränsvärdet för statistisk signifikans men även att dessa tenderar att vara spridda över hela det mänskliga genomet. Genvarianter som är lokaliserade i samtliga av våra kromosomer bidrar således till att förklara individuella skillnader i utbildningslängd.
Genetiska könsskillnader?
Vi har 46 kromosomer i våra celler, ordnade i 23 par. Varje par består av två kromosomer som vi har ärvt från vardera av våra föräldrar. Samtliga utom ett av paren är lika för både könen och kallas för autosomala kromosomer. Det återstående paret, eller könskromosomerna, skiljer sig emellertid mellan könen där kvinnor har två X-kromosomer (XX), medan män har en X och en Y-kromosom (XY).
Den observante läsaren har nog noterat att Manhattan-figurerna enbart inkluderar de autosomala kromosomerna. Könskromosomerna är mer vanskliga att analysera av diverse tekniska skäl. Exempelvis tenderar olika kopior av X-kromosomerna inom kvinnor att inaktiveras för att generna inte ska producera dubbelt så många proteiner i förhållande till män.
I den aktuella studien kunde forskarna i separata analyser med ett delurval om cirka 700 000 deltagare undersöka hur pass mycket av de individuella skillnaderna i utbildningsnivå som genvarianter på X-kromosomen förklarade. Tillsammans förklarade dessa en försvinnande liten andel av variationen, eller närmare 0,3 procent.
Forskarna fann heller inget stöd för att deras huvudanalyser förklarades av skillnader mellan deltagarnas kön. När de undersökte den genetiska korrelationen mellan resultaten för män och kvinnor fann de inget stöd för att den var mindre än 1, alltså en perfekt genetisk korrelation. Det betyder med andra ord att det i huvudsak är samma genvarianter i de 22 autosomala kromosomerna som förklarar skillnader i utbildningsnivå bland såväl män som kvinnor.
Heterogena samband
Den aktuella studien undersökte 64 separata datamaterial med DNA-prover och uppgifter om deltagarnas högsta uppnådda utbildningsnivå. Ett av studiens syften var att analysera huruvida sambanden mellan identifierade genvarianter och individuella skillnader i utbildningsnivå varierade mellan datamaterialen, med tanke på att de genomfördes i länder med betydande historiska, institutionella och genetiska skillnader.
Resultatet visade att 52 procent av de genetiska sambanden överlappade mellan datamaterialen (r=0,72; r^2=0,52). Denna överlappande andel indikerar att en betydande del av de genetiska associationerna med utbildningsnivå var robusta och replikerbara tvärs över olika populationer och kontexter. Samtidigt observerades en viss grad av heterogenitet i associationerna, vilket innebär att effekterna av vissa genetiska varianter varierade mellan olika datamängder. Forskarna undersökte därefter kontextuella faktorer på landsnivå som potentiellt kunde förklara denna variation, men den statistiska styrkan var otillräcklig för att dra några robusta slutsatser om de specifika faktorernas eventuella inverkan.
Hur beräknas polygena index?
Ni som har följt mitt arbete under en längre tid har säkert hört mig diskutera potentialen av att använda genetiska tester för att i ett tidigt skede identifiera barn i riskzonen för att utveckla svårigheter i skolan. Tanken med detta är att det vore fördelaktigt för att kunna erbjuda den gruppen barn mer omfattande individualiserade stödåtgärder så tidigt som möjligt för att på så vis minska deras risker för ett framtida misslyckande i skolan. Med tiden har jag emellertid blivit allt mer skeptiskt inställd till förverkligandet av sådana möjligheter. Orsakerna till min skepticism kommer att framgå i inläggets resterande del.
Hur kan man beräkna en persons genetiska anlag för utbildningslängd? Först måste vi veta vad de enskilda genvarianterna (enbaspolymorfier eller SNP:ar) har för effektstorlekar. Den aktuella helgenomstudiens sammanfattande statistik med samtliga skattade effektstorlekar för de identifierade genvarianterna finns tillgänglig för godkända forskare att ladda ned här.
Figuren nedan visar en förenklad version av den sammanfattande statistiken. Varje rad i tabellen avser en enskild genvariant (se rsID som diskuterades ovan) med ytterligare en kolumn som ger oss effektstorleken (b̂) eller sambandet mellan genvarianten och utbildningsnivå mätt i antal utbildningsår (EduYears).

Antag att vi har analyserat DNA-prov från en individ som inte ingick i den aktuella studien (extern deltagare) och identifierat vilka genvarianter personen bär på. Kolumnen "Allele" i tabellen nedan visar antalet alleler (genetisk variation kopplade till en viss egenskap) som individen bär på. Eftersom vi har ett par av varje kromosom, kan vi tolka antalet alleler på följande sätt:
0: Individen har inga alleler för den specifika genvarianten.
1: Individen har en allel på en av sina kromosomer.
2: Individen har en allel på båda sina kromosomer.
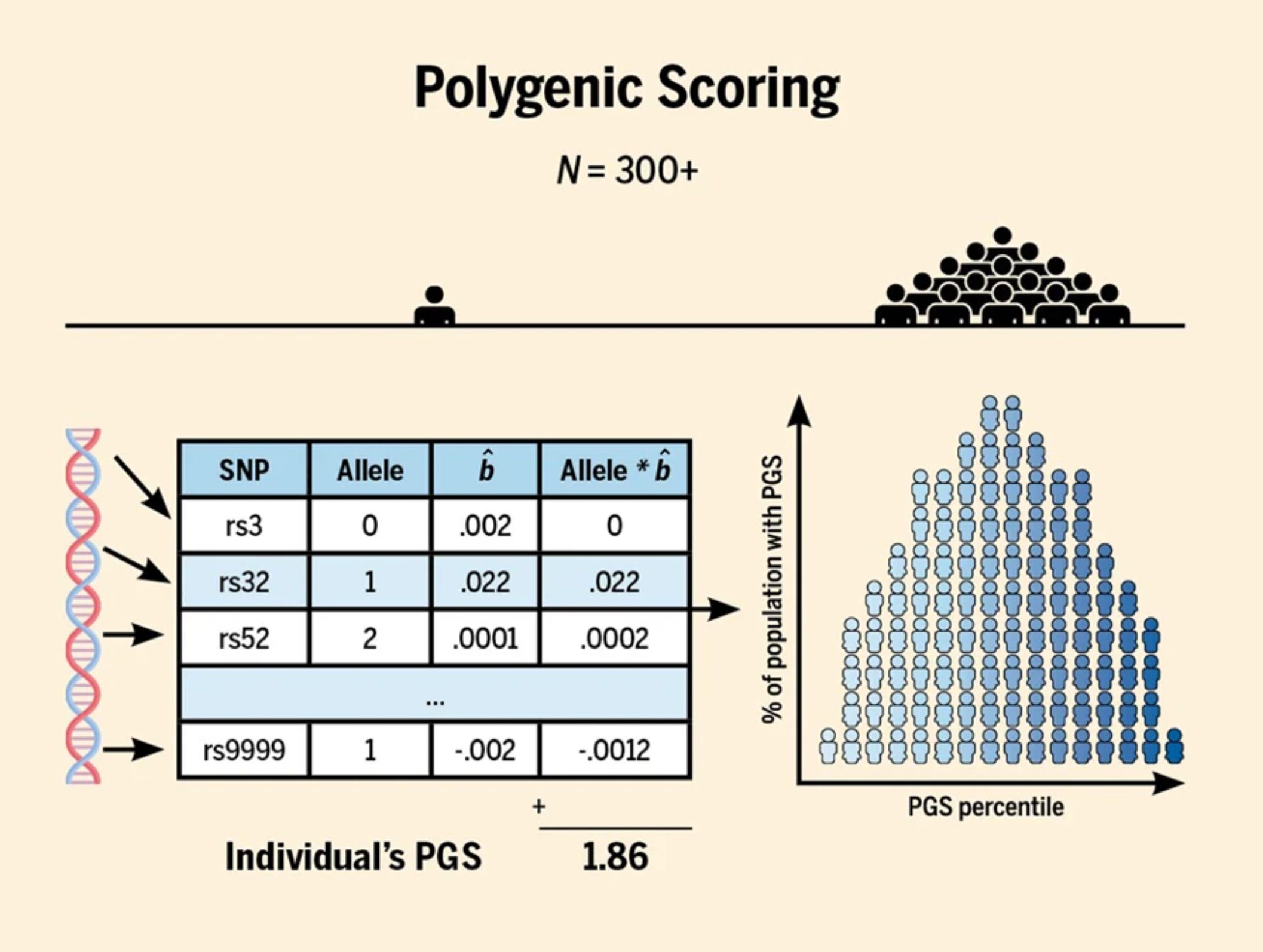
För att illustrera detta, låt oss anta att tymin (T) är allelen som är associerad med högre utbildningsnivå för enbaspolymorfierna rs3, rs32 och rs52. Då avser värden i kolumnen “Allele” följande:
0: Individen har en annan allel (C, A eller G) på båda kromosomerna.
1: Individen har T på en kromosom och en annan allel (C, A eller G) på den andra kromosomen.
2: Individen har T på båda kromosomerna för den specifika positionen.
Nästa steg är att multiplicera antalet alleler som en person bär på med effektstorleken för den specifika riskvarianten. Effektstorleken representerar hur starkt associerad en viss genvariant är till en viss egenskap, vilket här utgörs av utbildningsnivå. Genom att summera alla dessa produkter för varje genvariant hos en individ får vi fram individens polygena poängsumma (PGS) som även kallas för polygeniskt index (PGI).3
Begreppet “polygen” introducerades tidigare och hänvisar till att poängsumman eller indexet baseras på information från flera gener. Polygena index tar med andra ord hänsyn till den samlade effekten av en individs genetiska predispositioner för en viss egenskap. Det är dock viktigt att återigen betona att vi med sedvanliga helgenomstudier enbart fångar upp en mindre andel av individers genetiska predispositioner. Med större och bättre helgenomstudier kommer vi att kunna fånga upp en allt högre andel sådana influenser.
Om vi beräknar det polygena indexet för ett större antal individer från ett relativt representativt urval kommer vi att se att poängsumman tenderar att följa en normalfördelning. Detta innebär att majoriteten av befolkningen bär på ett genomsnittligt antal genvarianter kopplade till en viss egenskap, medan ett fåtal individer har antingen betydligt fler eller betydligt färre av sådana genvarianter.
Hur informativa är polygena index baserade på den aktuella studien?
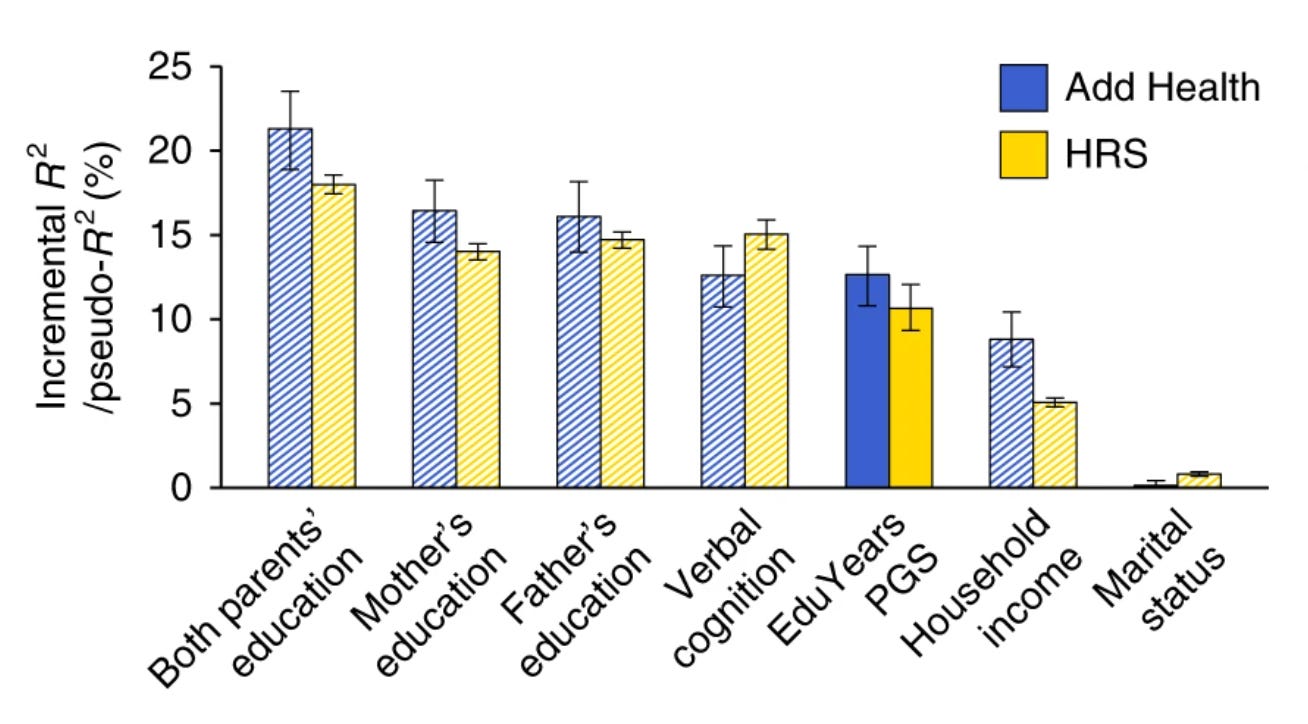
Förutom de datamaterial som användes i studien hade forskarna tillgång till två externa datamaterial med information om totalt 13 400 deltagare. Dessa datamaterial var Add Health (4 800 deltagare) och Health and Retirement Study (HRS) (8 600 deltagare). Eftersom information om DNA-prover och högsta uppnådda utbildningsnivå fanns tillgänglig för samtliga deltagare kunde forskarna beräkna ett polygent index för utbildningsnivå för varje person.
Forskarna delade sedan in deltagarna i fem jämnstora grupper baserat på deras genomsnittliga polygena indexvärden (kvintiler). Resultaten visade att bland gruppen med de lägsta indexvärdena hade ungefär en tiondel avklarat högre studier. I gruppen med de högsta indexvärdena var motsvarande siffra 45-55 procent. Det fanns en gradvis ökning av andelen individer med avklarade högre studier i takt med att det polygena indexet ökade. Detta tyder på att fler genvarianter associerade med högre utbildningsnivå i genomsnitt är associerade med att individen faktiskt uppnår en högre utbildningsnivå.
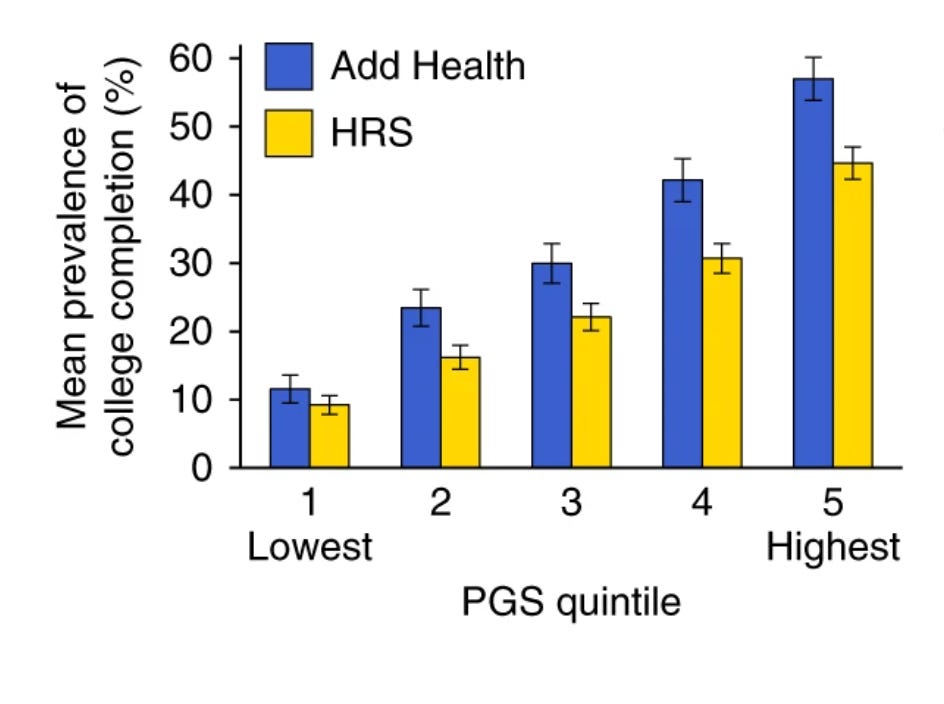
Dessa siffror kan se något dramatiska ut. Om vi beaktar hela fördelningen av deltagarnas utbildningsnivåer och inte enbart huruvida de har klarat av högre studier kan vi konstatera att individuella skillnader i det polygena indexet för utbildningsnivå förklarar mellan 11 och 13 procent av variationen i utbildningsnivå. Det må inte låta som särskilt mycket men betänk då att deltagarnas hushållsinkomster förklarar mellan cirka 5-10 procent av samma variation i utbildningsnivå.
Vad har de identifierade genvarianterna för biologiska funktioner?
För att validera fynden från helgenomstudier av specifika utfall, som utbildningsnivå, är det avgörande att utforska de identifierade genvarianternas biologiska funktioner. I den aktuella studien genomfördes detta med ett flertal metodologiska angreppssätt.
Första fasen av analysen fokuserade på att kvantifiera nivåerna av genuttrycken bland de identifierade genvarianterna i jämförelse med slumpmässigt utvalda genvarianter i 180 mänskliga vävnader och celltyper. Resultaten visade en signifikant uppreglering av de identifierade genvarianterna i vävnader och celler relaterade till det centrala nervsystemet, specifikt i hjärnregionerna hippocampus och cerebrala cortex. Dessa hjärnregioner utgör en central del av en rad kognitiva funktioner, inklusive inlärning, abstrakt tänkande, problemlösning, planering och minneshantering. De spelar dessutom en avgörande roll i vår hantering av sinnesintryck, rörelseförmågor och känslomässig bearbetning.
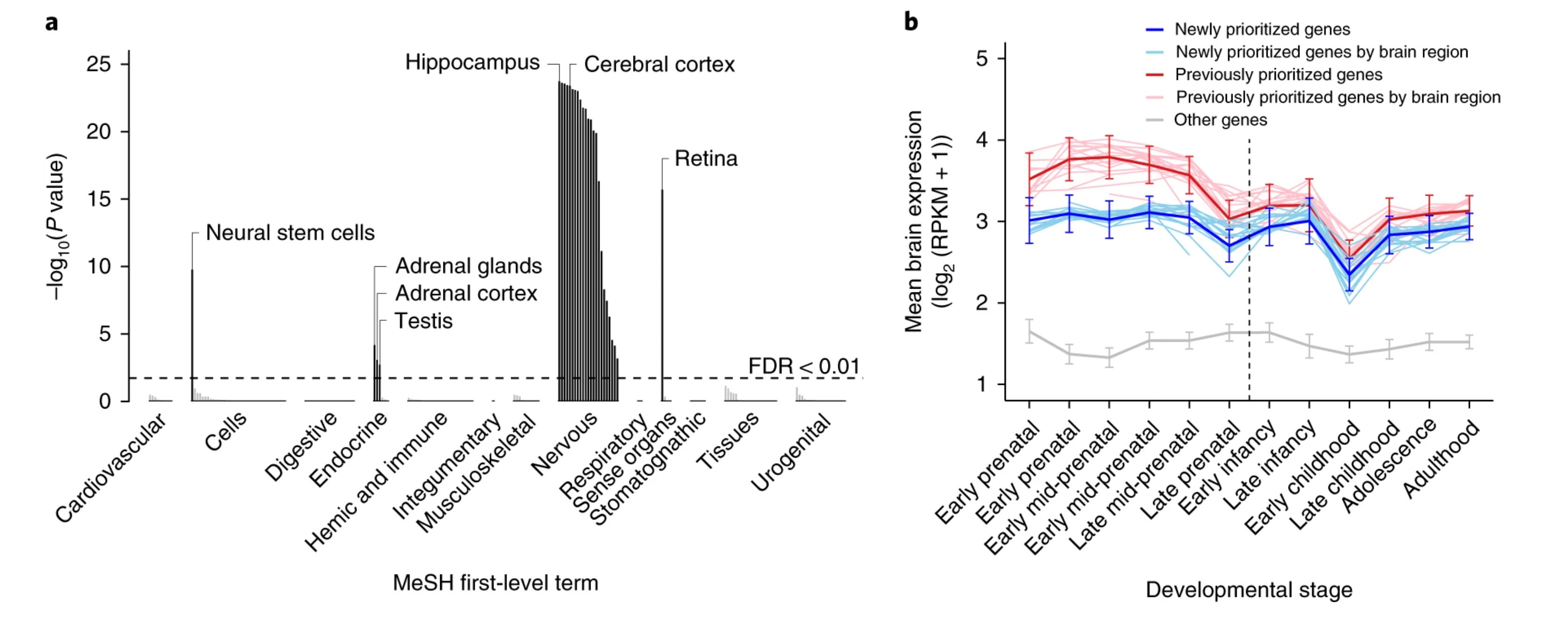
Den andra delanalysen fokuserade på att kartlägga uttrycksnivåerna av de nyligen identifierade genvarianterna i hjärnceller under avgörande faser av hjärnans utveckling. Tidigare trodde många forskare att de relevanta generna var som mest aktiva under fosterstadiet, men nu visade det sig att de identifierade genvarianterna är viktiga under hela livsförloppet, såväl före som efter födseln.
Mer omfattande genetiska korrelationer
De genvarianter som identifierades i den aktuella studien är inte unika för utbildningsnivå utan överlappar med genvarianter för en mängd andra utfall. Med hjälp av sammanfattande statistik från den aktuella studien och helgenomstudier för andra utfall kunde Kathryn Paige Harden, professor i beteendegenetik vid University of Texas at Austin, och Philipp D. Koellinger, professor i samhällsvetenskaplig genomik vid Fria universitetet Amsterdam (Vrije Universiteit Amsterdam) undersöka de genetiska korrelationerna emellan utfallen. Resultaten presenterades i översiktsartikeln “Using genetics for social science” som publicerades i Nature Human Behavior (2020).
Det visade sig att genvarianter som var associerade med högre utbildningsnivå var associerade med genvarianter som i sin tur var associerade med lägre kroppsmassa (BMI), kroppsfettprocent, typ 2-diabetes, och kolesterol. Samtidigt förelåg det positiva genetiska korrelationer mellan utbildningsnivå och födelsevikt, huvudomfång vid födseln och intelligensmätningar under barndomen. Bland fertilitetsutfallen noterade forskarna ett starkt positivt genetiskt samband mellan utbildningsnivå och högre ålder vid det förstfödda barnet och ett negativt genetiskt samband med antalet barn.

Det var mer blandade resultat för psykiatriska tillstånd där depressiva symtom, neuroticism och Alzheimers sjukdom var negativt genetiskt korrelerade med utbildningsnivå medan anorexia nervosa, autismspektrumtillstånd, bipolär sjukdom och schizofreni var positivt genetiskt korrelerade med utbildningsnivå. De senare resultaten har inte replikerats i helgenomstudier av intelligens, vilket jag har anledning att återkomma till i senare inlägg.
Det finns en rad andra spännande fynd i figuren men den större lärdomen är att de identifierade genvarianterna för utbildningsnivå har starka pleiotropiska effekter, vilket innebär att de samtidigt påverkar flera andra utfall. Fynden visar på vikten av att beakta ärftliga faktorer i epidemiologiska och samhällsvetenskapliga studier som undersöker utbildningsnivå, antingen som utfall eller exponering.